SQL Server Performance by Query Type
 Dan Kolz
November 3, 2014
Dan Kolz
November 3, 2014
Summary
The SQL Server 2100 parameter limit is a pain to code around when selecting lots of rows by ID and using batches of parameterized queries doesn't seem to perform very well.
This performance study shows that you should definitely stop using batched parameterized queries for selecting rows by ID. They should be replaced with a temporary table approach for large batches, or constructed SQL strings if temporary tables prove unworkable.
Approaches Overview
This study looks at the performance of four approaches to finding many rows by ID.
Parameterized Query Batches - Executing several parameterized queries, as many as are needed to select all of the rows
select * from mytable where id in (?, ?, ?, ..., ?, ?)
Constructed SQL - Standard SQL with many values as part of the IN condition
select * from mytable where id in (1, 2, 3, ..., 3013, 3014)
Temporary Tables - Inserting the keys into a temporary table and joining the temporary table to the table being queried
create table #temptable (id int);
insert into #temptable (id) values (1), (2), (3)
select * from mytable mt inner join #temptable tt on mt.id = tt.id
Table Variables - Like the temporary tables approach but using a table variable instead of a temporary table
DECLARE @IDHOLDER TABLE (id int primary key);
insert into @IDHOLDER(id) select * from ( values (92), (0), (26) ) as X(a)
select t1.* from mytable t1 inner join @IDHOLDER t2 on t1.id = t2.id
The Scenarios
There are two different sizes of queries done by different parts of the code. Although this study is primarily interested in optimizing for numbers of parameters greater than 2100, we want to make sure a new approach isn't bad for the small batches.
10k selected IDs, Big Tables
Microsoft SQL Server has a limit on the number of parameters that a parameterized query can have (2100). However, many of our queries have a total number of IDs selected far greater. Currently we are using batches of IDs with parameterized queries to extract the entire set. However, these operations are cumbersome to code and don't seem to perform as well as we'd like.
Hundreds of selected IDs, big tables
Other sections of our code operate on relatively smaller fixed batch sizes of about 250 IDs selected. While this code doesn't have the acrobatics of working with large total numbers of row IDs, it is among our most frequently executed code and fairly modest improvements to its speed may have big impacts on application scaling.
The Test Database
The test database is Microsoft SQL Server 2008r2 running inside a Window 7 VM with a 4 CPU cores, 6GB of RAM, and the PAE extensions on. The disk image is on 7200 RPM spinning media. In my testing there seemed always to be free memory so I think that is not a limiting factor.
I used four tables with similar formats but a varying number of rows: 100, 10k, 1m, 50m. The table create DDL was:
create table <table_name> (id int IDENTITY(1,1) PRIMARY KEY, age int, nonid int, name varchar(1000))
Each row always had data for all columns. The smaller three tables had 70 characters of data for the name column. The 50m row table had only 5 characters.
Selection Approaches
Java code was used to conduct the test (the language most of Scoreboard is written in). All tests were performed using JDBC and the Microsoft sqljdbc driver version 4. All tests where run in a newly created connection set to use transactions and had their memory cache cleared by running:
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE
In spot testing leaving the cache uncleared did improve performance but did not seem to change the relative performance of the queries.
Parameterized Query Batches
A popular technique is to create parameterized queries for database access. The query looks like:
select * from mytable where id in (?, ?, ?, ..., ?, ?)
Using this mechanism has two primary advantages: it protects against SQL injection attacks and allows reuse of a query, avoiding the time it takes for the database to re-parse the query string for subsequent uses. When the query is executed, specific values are passed and substituted for the question marks.
There is a disadvantage to this mechanism which is that only 2100 parameters can be used in any one query. This, as mentioned above, causes us to have to execute our larger queries in batches which requires some additional coding and seems intuitively like it should be slower than a single query.
Constructed SQL
A second approach is to construct an SQL string with the actual values being searched for. While there is a limit to the number of parameters in a parameterized query, there isn't a hard limit on the number of values in a query. The SQL for this approach looks like:
select * from mytable where id in (1, 2, 3, ..., 3004, 3005)
This approach offers an unlimited number of selected IDs but special steps have to be taken to prevent SQL injection attacks. Additionally, constructing the SQL results in code that breaks up the parts of the SQL statement, making them potentially difficult to read and change.
Temporary Tables
The third approach is to insert the ID values into a temporary table and then join that temporary table to the table in question. This results in SQL that looks like:
create table #temptable (id int primary key);
insert into #temptable (id) values (1), (2), (3)
select * from mytable mt inner join #temptable tt on mt.id = tt.id
The advantage of this approach is that the selection itself uses a mechanism (table join) which we know gets a lot of use and has presumably been optimized to the extreme by the SQL Server product team. Additionally, the temporary table once constructed can be reused without the cost of recreating it. If we need to perform different queries with the same ID set, this could be an advantage.
The disadvantage is that this style of query is more complicated. Additionally, Microsoft SQL server will only insert 1000 rows into a table with a single insert query. There are some ways to work around this, but it makes this style even more complicates since multiple inserts need to be run for parameters over 1000, instead of just over 2100.
It is commonly believed that temporary tables are in-memory-only objects. This is not true for Microsoft SQL Server. MySQL has a memory only storage engine which is probably perfect for this technique. However, MS SQL Server temporary tables live only in memory if they are small (says one source) but probably have an existence on disk in the tempdb.
There are some ways to work around this (see the section on inserts below) but it remains something to be worked around.
For temporary tables, the time reported include the time to insert the data but NOT the time it takes to create the temporary table. During testing I found that just issuing the create temporary table statement could take several seconds if I was in a connection that had been used for a previous test run. However, this was not the case if I created all of the temporary tables as the first step in the test or if I used a new connection to test each table in a test run. This intuitively points to a locking or resource contention issue but I was unable to determine what it was. Since time is always short and there are several work arounds, I decided to punt on this problem for the time being.
Table Variables
The forth approach uses SQL Server's ability to assign a table of data to a variable. This variable can then be treated like table name and used in an inner join. The queries look something like:
DECLARE @IDHOLDER TABLE (id int primary key);
insert into @IDHOLDER(id) values (92), (0), (26)
select t1.* from mytable t1 inner join @IDHOLDER t2 on t1.id = t2.id
This is conceptually the same as using a temporary table. However, aside from the limitations that we don't care about for these tests, the major limitation is that the table variable can only be used for a single query. Even subsequent queries later in the same transaction won't be able to use a previously declared table variable. The hope is that an more ephemeral mechanism will be less likely to use disk and therefor faster. However, it is thought that while table variable perform nicely for small data sets (less than 1000 rows) they have problems with large numbers of rows.
Among the additional disadvantages is that SQL Server is thought to sometimes create odd or inefficient query plans with table variables. Although this might be a big deal with complicated queries, it seems like it would be pretty tough for SQL Server to screw up a two table join.
Insert Approaches
Given SQL Server's limitation of inserting no more than 1000 rows and having two mechanism that relied on tables being populated (temporary tables and table variables), I did some tests to see which is the most efficient way of inserting id rows into a table.
Single Parameter JDBC Batches
This approach used a JDBC prepared statement with one parameter and JDBC's addBatch method. Although I'm not sure the JDBC implementation actually works this way, it is conceptually equivalent to have one insert statement for each row but composed as a single string and submitted as a single command.
insert into #tt1 values (?)
Multiple Parameter JDBC Batches
This is similar to the previous method, but each prepared statement contains up to 2000 parameters.
insert into #tt1 values (?, ?, ?, ..., ?)
Constructed SQL with Multiple Insert Statements
This method involves creating one long SQL string that has one or more insert statements where each insert statement would be inserting up to 1000 rows.
insert into #tt1 values (1), (2), ... (1000); insert into #tt1 values (1001), (1002)...
Constructed SQL with Union
This also involved composing an SQL string but used the UNION keyword.
insert into #tt1 select 1 UNION ALL select 2 UNION ALL ...
Constructed SQL with Values Sub-table
This also involved as single SQL statement put used the values subtable format to insert all the rows in a single query.
insert into #tt1 select * from (values (1), (2), ... ) as X(a)
Insert Result Summary
It seems clear that for small data sets it doesn't matter what you do. For large databases the both JDBC methods were the best. If only a string of SQL is an option, the string of multiple insert statements was by far the the best performer.
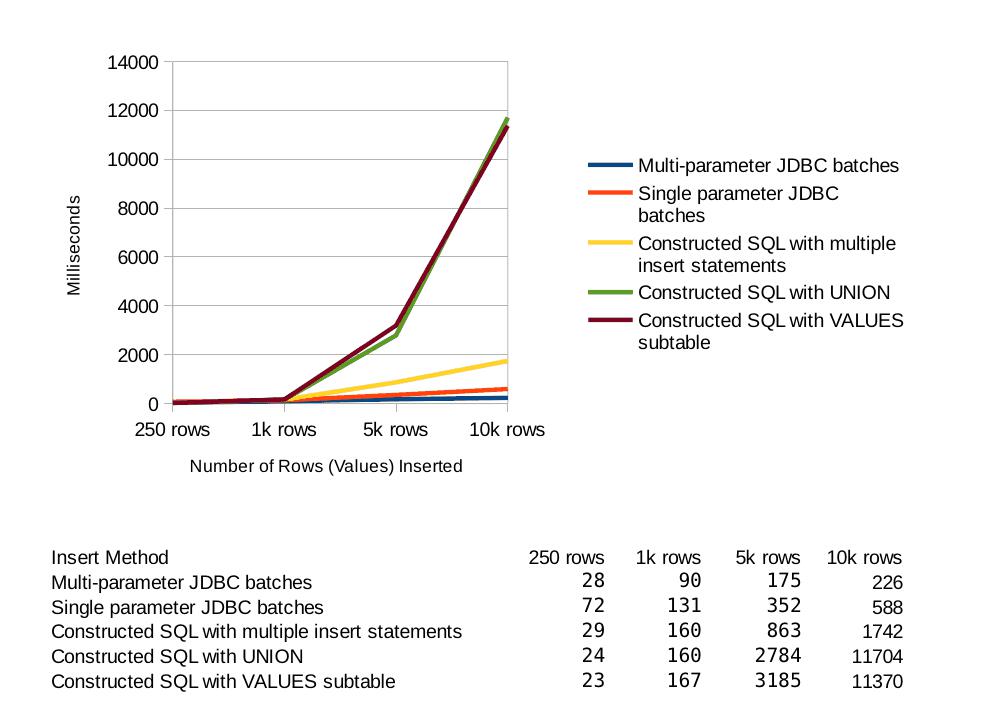
Selection Results
A word about variability: In these tests I found the results to vary significantly. For shorter times ( < 200ms), it might be as much as 30% or 40%. This is what you'd expect on a system with spinning media also engaged in other light tasks such as email, playing music (listening to Sting right now), and working with documents and spreadsheets. Larger values seemed to vary by about 10% or 15%.
250 Parameters/IDs Selected
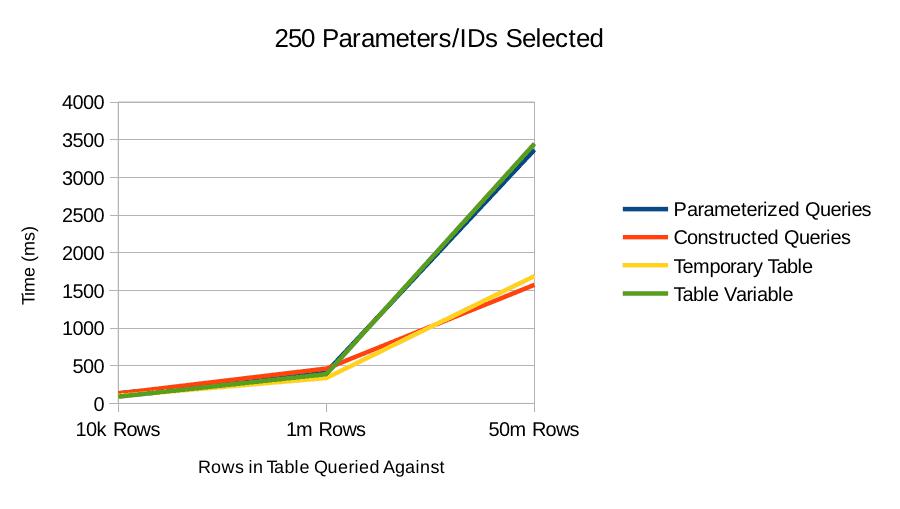
For 250 IDs selected against small tables, it seems not to matter very much how you perform the query. Given the variability I noticed, these are all actually about the same number.

For tables with lots of rows, it's clear that the temporary table and constructed SQL query approaches are superior. It's odd to me that the table variable doesn't perform better. When I look at the actual query plan for the table variable query, it shows that the table variable does have an index and it is getting used.
1000 Parameters/IDs Selected
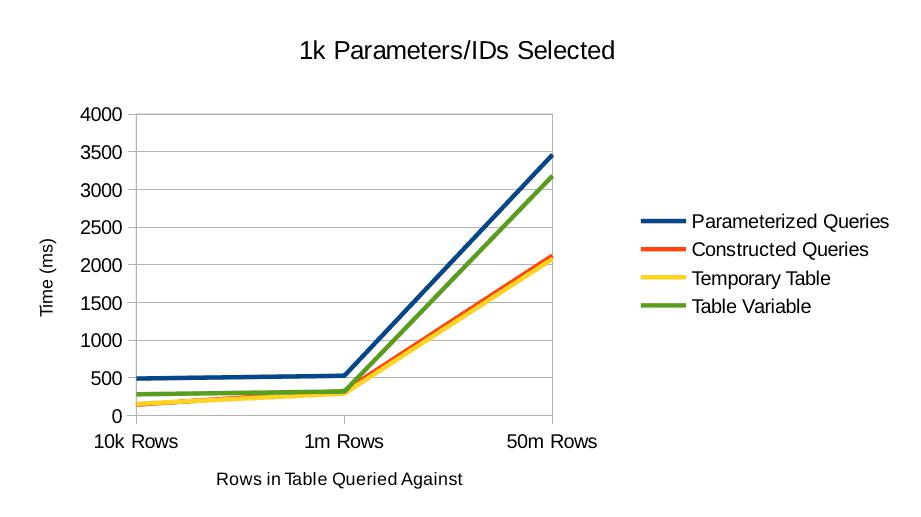
With 1000 IDs being selected we start to see a separation in performance even for small tables. Once again, the temporary table and constructed query approaches are showing the best performance.
Note that in this test none of the approaches have had to resort to any sort of batching to get the query performed.
10k Parameters/IDs Selected
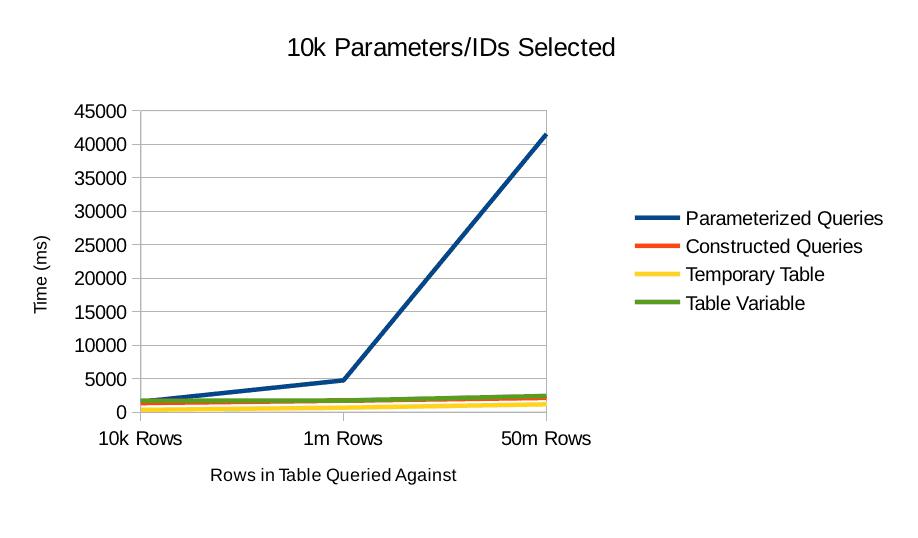
What's clear here is that the parameterized query approach is horrible when batching becomes necessary. It becomes especially bad the larger the table gets.
Let's see this again with only the best three to get an idea of the relative strengths of the better performing methods.
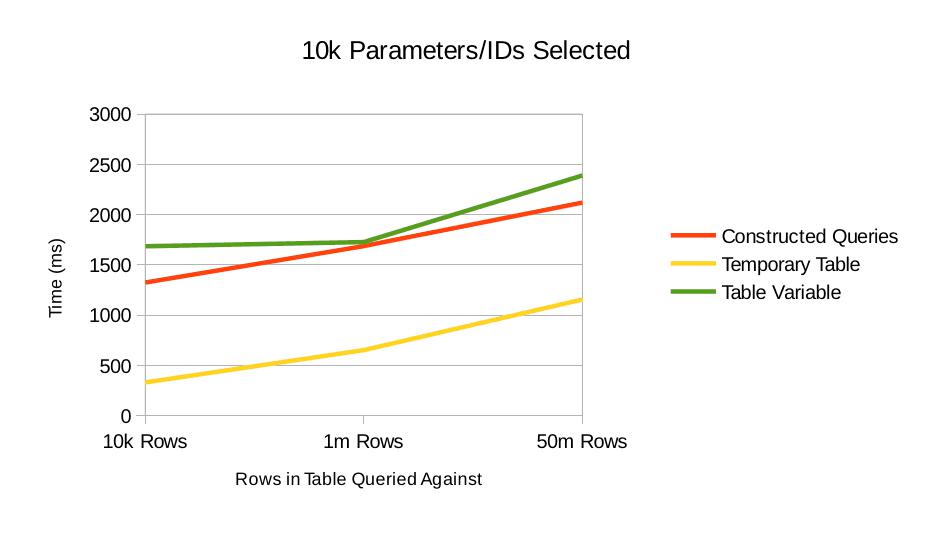
Here we see a shift from earlier runs. The table variable approach is performing on par with the constructed query approach even though the table variable requires batches of insert statements.
The query plan doesn't shed a lot of light on why the constructed query approach works so much more poorly (comparatively) than earlier runs. The plan shows that the constants of the IN condition are scanned once and an index seek is performed on the tables in question.
There's obviously a heavier load on parser because each of these queries have a greater length. There's nothing about the constructed query which should be particularly difficult to parse though.
The temporary table approach really shines here even though we had to insert 10k values into it. As the insert test shows, in the 10k parameter case the insert is probably taking 20% of the time. I mentioned earlier that one advantage of this approach is that the table could be reused, saving the cost of having to do the insert. While true, at least at this scale, that seems like it would be only a modest performance bump.
Things of Interest
You may notice that the time to select 10k parameters is actually less for some approaches (like the table variable) than the time to select 1k parameters on the same tables. I admit to being a little mystified about this. The effect remains even when I change the order so that the 10k parameters test is run first.
Summary
You should definitely stop using batched parameterized queries for selecting rows by ID. They were the bottom performer in every test. They should be replaced with temporary tables if you're willing to do a little work to make sure you're not hitting the create temporary table delay. If, for whatever reason, the temp table approach is not chosen, you should use the constructed query approach within a framework that prevents SQL injection attacks.





Demo then Free Trial
Schedule a personalized tour of Spider Impact, then start your free 30-day trial with your data.